electronic discovery (e-discovery or ediscovery)

What is electronic discovery (e-discovery)?
Electronic discovery -- also called e-discovery or ediscovery -- is the process of obtaining and exchanging evidence in a legal case or investigation. E-discovery is used in the initial phases of litigation when involved parties are required to provide relevant records and evidence related to a case. This process includes obtaining and exchanging electronic data that is sought, located, secured and searched for with the intent of using it as evidence.
E-discovery can be conducted offline on a specific computer, or it can be done on a network. The data collected in the e-discovery process includes any information that is in an electronic format, including emails, texts and social media posts.
Digital data is extremely well suited for investigation. It can be electronically searched versus paper documents, which must be reviewed manually. Digital data contains metadata, including timestamps, file properties, and information on the author and recipient. Digital data is also difficult or impossible to completely destroy, particularly once it gets into a network where it is resides on multiple hard drives and digital files. The most reliable way to ensure a computer file is destroyed is to physically destroy every hard drive where the file has been stored.
Types of electronically stored information
In the process of electronic discovery, all types of data can serve as evidence. This can include electronic documents, such as text, images, audio, video, calendars, instant messages, cellphone data, databases, spreadsheets, animation, websites and computer programs. Email can be an especially valuable source of evidence in civil or criminal litigation because people are often less careful in these exchanges than in hard-copy correspondence, such as written memos and postal letters.
What is e-discovery used for?
E-discovery is used in civil procedures and legal processes in areas such as the U.S. federal court system. Other court systems throughout the world also have rules pertaining to electronic discovery. For example, in England, it is a civil procedure and has an agreed-upon process.
Before e-discovery, parties in litigation exchange relevant information in physical documents. E-discovery broadened this process to include electronically stored information (ESI). Counsel from both sides find and preserve relevant ESI, making e-discovery requests and challenges throughout the litigation process.
How does the e-discovery process work?
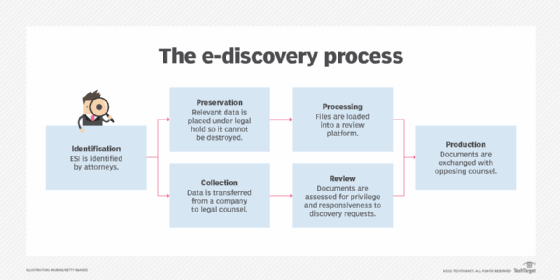
The process of discovery begins when a lawsuit appears imminent, up to when digital evidence is presented in court. Attorneys from both sides will determine the scope of e-discovery. The following is a simple description of the e-discovery process:
- Identification. ESI is identified by attorneys. E-discovery requests and challenges are made.
- Preservation. Data that is identified as potentially relevant is placed under legal hold so it cannot be destroyed. Failure to preserve data will lead to sanctions and fines if the lost data puts the defense at a disadvantage.
- Collection. Data is transferred from a company to legal counsel. The legal counsel determines the data's relevance.
- Processing. Files are loaded into a review platform. Data is usually converted into a PDF (Portable Document Format) or TIFF (Tag Image File Format) for court.
- Review. The review process assesses documents for privilege and responsiveness to discovery requests.
- Production. Documents are exchanged with opposing counsels.
Legal issues with e-discovery
E-discovery is an evolving field that goes far beyond just technology. It gives rise to many legal, constitutional, political, security and personal data privacy issues, many of which have yet to be resolved. For example, the timeline for e-discovery is relatively short, and parties can face penalties if they fail to meet deadlines to provide ESI.
In the past, data has also been leaked unintentionally due to the e-discovery process. In 2017, an attorney for Wells Fargo accidently sent opposing counsel confidential information about the bank's clientele. The information included customer names, Social Security numbers and financial details.
Two other issues with e-discovery include collection of new data types and reduction of cost. The cost of e-discovery is directly related to how much data needs to be collected and retained. As more and new types of data are collected, more money needs to be spent on storage, information technology and management. The review phase is also typically expensive, as individual documents need to be reviewed for relevance and privilege. The lawyers and managers who make up in-house counsel and are typically in charge of costs are pressured to reduce costs where possible, including in data management. This may lead to further complications and fines if an organization cannot properly manage all its collected data.
Emerging trends in e-discovery
One of the recent shifts in e-discovery is the larger-scale adoption of video conferencing and collaboration tools. Due to the COVID-19 pandemic, more organizations and individuals worked remotely. Document reviews that did not need reviewers sitting in close proximity could be hosted over platforms such as Zoom or Microsoft Teams. Virtual managed reviews have become a more popular trend that may stay as a practice.
Technology-assisted review and predictive coding are other trends that use supervised machine learning and rules-based approaches in order to find relevance, responsiveness and privileges of ESI.
Differences between e-discovery and digital forensics
Computer forensics, also called cyber forensics, is a specialized form of e-discovery in which an investigation is carried out on the contents of the hard drive of a specific computer. After physically isolating the computer, investigators make a digital copy of the hard drive. Then, the original computer is locked in a secure facility to maintain its pristine condition. All investigation is done on the digital copy.
E-discovery and digital forensics are similar processes, as both involve identifying, collecting and preserving data. However, the main differences between the terms are in how the data is presented and who is analyzing it.
In computer forensics, a forensics expert is in charge of protecting data integrity and bringing forth stored data. In e-discovery, attorneys handle these processes. Digital forensics also uses different software applications.
E-discovery firms also do not analyze the data they collect, nor do they determine the intent of a user or provide legal advice -- as forensic experts do. Rather, e-discovery gathers and organizes information for others to view.
Learn more about computer forensics and its role in risk management.
Continue Reading About electronic discovery (e-discovery or ediscovery)
Dig Deeper on Data security and privacy
-
![]()
Questions raised over NHS deletion of thousands of emails during whistleblower tribunal
By: Tommy Greene
-
![]()
Epic Study Finds Health Data Exchange Lowers Risk of Code Blue
By: Hannah Nelson
-
![]()
Expert guide to e-discovery
By: Martin Nikel
-
![]()
How legal disclosure failures disrupted the Post Office Horizon inquiry
By: Martin Nikel



